Hoe SurveyMonkey aan haar gegevens komt
We stellen enquêtevragen op een ongeëvenaarde schaal om kwalitatief hoogwaardige informatie te krijgen.
Elke dag voeren meer dan 2 miljoen mensen gesprekken met behulp van SurveyMonkey.
En dat zijn niet alleen klanten, werkgevers, marktonderzoekers of deelnemers aan evenementen. Mensen over de hele wereld gebruiken SurveyMonkey om feedback te geven op alles wat u zich maar kunt voorstellen. Een heel klein deel van deze mensen vragen wij naar hun mening over belangrijke zaken, en zo krijgen wij ongekende toegang tot een steekproef van de Amerikaanse populatie.
Dit geeft ons de kans het Amerikaanse publiek te peilen over hun mening over belangrijke actuele gebeurtenissen, terwijl ons team van vakkundige enquêtewetenschappers ervoor zorgt dat de steekproef van individuele eenheden representatief is voor de Amerikaanse populatie.
Hoe komt SurveyMonkey aan haar gegevens? We leggen het u stap voor stap uit.
1. Elke dag doen meer dan 2 miljoen mensen enquêtes op het SurveyMonkey-platform.

2. Een willekeurige selectie van die mensen wordt uitgenodigd om deel te nemen aan een optionele enquête.

3. Nadat zij de enquête hebben ingevuld, filteren wij de mensen die de enquête niet hebben voltooid eruit (non-respons).

4. Onze enquêtewetenschappers passen de data zorgvuldig aan zodat het resultaat een accurate vertegenwoordiging is van de steekproefpopulatie.
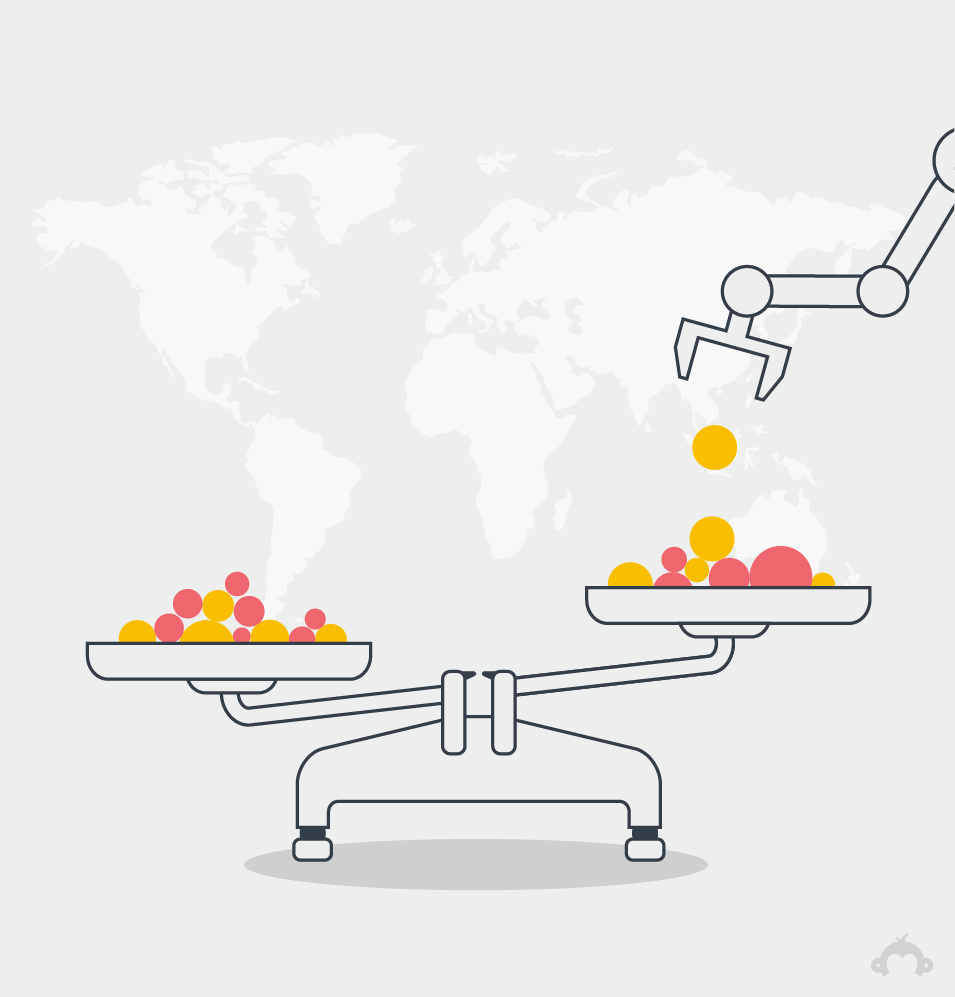
5. Wat betekent dat? Wanneer groepen in onze steekproef niet precies overeenkomen met de grotere populatie, gebruiken we geavanceerde statistische inferenties om ze in evenwicht te brengen.

6. Nu gaan we kijken naar de resultaten. We verzamelen reacties en voegen ze samen tot een begrijpelijke momentopname van wat mensen denken.
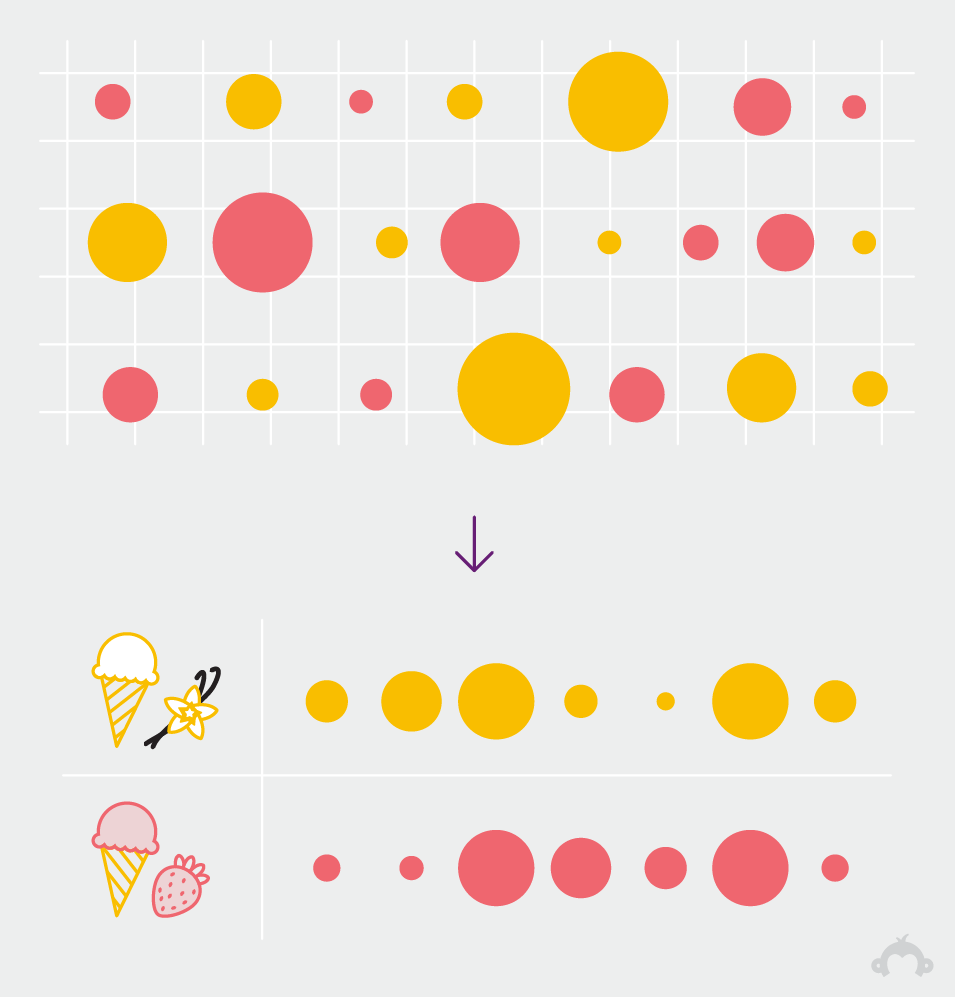
7. Dankzij de grote schaal van onze steekproeven, kunnen we meningen vaststellen die anderen niet kunnen aanwijzen en krijgen we diepgaand inzicht in de publieke opinie en ervaringen.

Waarom u kunt vertrouwen op de gegevens van SurveyMonkey
Ons team van enquêtemethodologen en peilers staat achter onze data vanwege drie kernprincipes:
Schaal en diversiteit: Tijdens de miljoenen enquêtegesprekken die we elke dag voeren, praten we met mensen uit veel verschillende demografische groepen - artsen onder de 30, bouwvakkers in de Amerikaanse staat Maine of Aziatisch-Amerikaanse gepensioneerden. Onze respondenten worden onder meer onderverdeeld naar:
- Regio in de VS (zelfs tot staatsniveau)
- Leeftijd, geslacht, etnische afkomst
- Achtergrond (inkomen, functie, politieke voorkeur)
Known sampling: In tegenstelling tot sommige andere enquêtebedrijven, vragen we onze respondenten om hun persoonlijke informatie - we eigenen het ons niet zomaar toe. We verzamelen demografische informatie van al onze respondenten, wat ons een belangrijke context geeft voor onze resultaten. Het maakt ook een betere weging mogelijk van onze gegevensverzameling, waardoor deze nog accurater wordt.
Transparantie: Het is ons beleid om transparant te zijn over onze wegings- en steekproefmethoden. De details van onze enquêtemethodologie zijn toegankelijk voor iedereen. Wilt u ze zien? Vraag het ons!
De enquêtemethodologie van SurveyMonkey
Elke dag houdt ons SurveyMonkey-onderzoeksteam enquêtes over politiek, sports, actuele gebeurtenissen, de media en nog veel meer interessante gebieden. In 2016 enquêteerden we ruim 1 miljoen Amerikaanse stemmers en we zijn sindsdien alleen maar harder gaan werken. Ook hebben we onze enquêtemethoden iets aangepast. Bent u geïnteresseerd in ons huidige steekproefdesign, onze vragenlijsten, weegmethodologie en databeschikbaarheid? Lees dan deze pagina!
Hoe enquêteren wij?
Elke dag vullen ruim 2 miljoen mensen enquêtes in op het SurveyMonkey-platform die door andere gebruikers zijn gemaakt. We selecteren uit deze respondenten een willekeurige steekproef om vrijwillig mee te doen met onze onderzoeksenquêtes. Na het invullen van de initiële enquête, zien ze een pagina met dankwoord waarin ze worden uitgenodigd om een optionele enquête in te vullen. Dat zijn onze onderzoeksenquêtes die we doen in samenwerking met mediakanalen en andere organisaties.
Ons steekproefproces is vergelijkbaar met de traditionele peilingsmethodes, maar is aangepast aan het internettijdperk. Deelnemers worden niet meer willekeurig geselecteerd uit een lijst met telefoonnummers, maar uit onze diverse basis van dagelijkse enquêtedeelnemers. We vragen onze respondenten hoe oud ze zijn, waar ze geregistreerd zijn om te stemmen, in welke regio ze wonen en dergelijke … net als bij telefoonpeilingen.
Onze deelnemers zijn afkomstig uit alle 50 Amerikaanse staten en wonen in steden of op het platteland en alles wat daartussen zit. Omdat SurveyMonkey een online platform is, moeten alle respondenten voor het invullen van onze enquêtes toegang hebben tot het internet. Dat is steeds minder een beperkende factor, omdat internet steeds breder beschikbaar is en omdat meer en meer respondenten enquêtes invullen op hun mobiele telefoon of op een ander apparaat.
Wat voor vragen stellen we?
De onderzoeksenquêtes van SurveyMonkey zijn doorlopend actief; onze respondenten vullen onze optionele enquêtes 24 uur per dag, 7 dagen per week in. Alle enquêtes zijn in het Engels geschreven en soms worden ze vertaald naar het Spaans. We vragen respondenten altijd naar informatie over hun geslacht, ras/etniciteit, leeftijd, in welke staat ze wonen en opleidingsniveau. Deze data gebruiken we vervolgens om onze resultaten te wegen zodat ze een nationale vertegenwoordiging zijn.
We stellen met enige regelmaat vragen over identificatie met politieke partijen, waardering van de Amerikaanse president en zaken die respondenten aan het hart liggen zodat we aan de hand van de antwoorden veranderingen in trends kunnen volgen. Als er meerdere enquêtes tegelijk lopen, voegen we de reacties op deze vragen samen. Daarnaast bestaat er geen risico dat voorafgaande vragen in andere enquêtes de antwoorden van de respondenten beïnvloeden, omdat deze vragen altijd als eerste worden gesteld.
Hoe worden resultaten gewogen?
We hebben verschillende wegingsschema's waaruit we kunnen kiezen, afhankelijk van de steekproefgrootte en de doelpopulatie van elke enquête. Voor elk van de wegingsschema's die hieronder staan beschreven, gebruiken we de American Community Survey - ACS (Amerikaanse gemeenschapsenquête) uit 2015 van het Amerikaanse Census Bureau om schattingen te genereren die de meest actuele demografische samenstelling in de VS weergeven als het gaat om leeftijd, ras, geslacht, opleiding en geografische locatie. Alle respondenten moeten de enquêtevragen beantwoorden die worden gebruikt om deze parameters in elk van onze enquêtes te wegen.
- Weging nationale algemene bevolking (standaard)
Bij het tabuleren van nationale schattingen voor enquêtes met minder dan 10.000 respondenten, doen we een meerfase vergaring om nationale gewichten te creëren. Eerst definiëren we geografische eenheden per staat/indeling op basis van de populatieomvang per staat en indelingsclassificatie van de Census. Staten met meer dan vijf miljoen inwoners worden gedefinieerd als 'stand-alone units', terwijl kleinere staten worden gegroepeerd in een Censusindeling om secundaire geografische units te vormen. In de eerste fase van het vergaren, wordt de steekproef gewogen naar volwassen populatiegroottes van de geografische eenheden per staat/indeling om initiële wegingen te genereren. In de tweede fase van het vergaren worden initiële wegingen bijgesteld op basis van geslacht, leeftijd, ras en opleiding binnen elke Censusregio om aan te sluiten bij de doelen die zijn verkregen in de ACS. - Weging nationale algemene bevolking - grote steekproeven
Wanneer een nationale enquête meer dan 10.000 respondenten heeft, doen we een meerfasige vergaring om nationale gewichten te creëren. In de eerste fase van het vergaren, wordt de steekproef gewogen naar volwassen populatiegroottes van de 50 staten plus het District of Columbia om initiële gewichten te genereren. In de tweede fase van het vergaren worden initiële gewichten bijgesteld op basis van geslacht, leeftijd, ras en opleiding binnen elke Censusregio om aan te sluiten bij de doelen die zijn verkregen in de ACS. - Weging op staatsniveau
Voor enquêtes die zich richten op een bepaalde staat, zoals onze enquêtes vlak voor de speciale verkiezingen in Alabama, Virginia en New Jersey in 2017, gebruiken we vergaring om gewichten op staatsniveau te verkrijgen. We delen postcodes eerst in vijf groepen in op basis van hun populatiegrootte. We leiden het initiële respondentgewicht af van de geschatte steekproeffrequenties op de pagina met dankwoord van SurveyMonkey News binnen elk postcodegebied. Daarna vergaren we de initiële respondentgewichten op basis van geslacht, leeftijd, ras en opleiding in de staat zodat het overeen komt met de doelen die zijn verkregen in de ACS. - Weging op regionaal niveau
Voor enquêtes die zich richten op een bepaalde Amerikaanse regio, zoals onze peilingen in de zuidelijke staten voor het televisie- en radionetwerk NBC, gebruiken we de meerfase vergaring om wegingen op regionaal niveau te creëren. Eerst definiëren we geografische eenheden per staat/indeling op basis van de populatieomvang per staat en indelingsclassificatie van de Census in de gepeilde staten. Staten met meer dan vijf miljoen inwoners worden gedefinieerd als 'stand-alone units', terwijl kleinere staten worden gegroepeerd in een Censusindeling om secundaire geografische units te vormen. We delen postcodes eerst in vijf groepen in op basis van hun populatiegrootte in elke geografische eenheid. We leiden het initiële respondentgewicht af van de geschatte steekproeffrequenties op de pagina met dankwoord van SurveyMonkey binnen elk postcodegebied. Tijdens de eerste fase van het vergaren, worden de initiële gewichten gecontroleerd op basis van populatiegrootte van de geografische eenheid. In de tweede fase van het vergaren worden initiële gewichten bijgesteld op basis van geslacht, leeftijd, ras en opleiding om aan te sluiten bij de doelen die zijn verkregen in de ACS.
Wat is onze foutmarge
Enquêtes die zijn gebaseerd op aselecte designs kunnen een foutmargeschatting berekenen en rapporteren voor elke statistiek die ze produceren. U ziet vaak beschrijvingen als, 'deze enquête heeft een foutmarge van +/- 3,5 procentpunten'. Dat betekent dat als het verschil tussen twee schattingen binnen de foutmarge ligt, we niet met zekerheid kunnen zeggen welke groter is.
Onderzoeksenquêtes van SurveyMonkey hebben geen aselect ontwerp, omdat er geen goed gedefinieerd steekproefkader is voor respondenten van SurveyMonkey-enquêtes. Daarom rapporteren we geen foutmarge om verwarring te voorkomen. In plaats daarvan gebruiken we een 'gemodelleerde foutschatting' die wordt berekend met behulp van een simpele betrouwbaarheidsinterval. Volgens de American Association for Public Opinion Research (AAPOR) is deze methode de aanbevolen procedure voor selecte enquêtes.
Dit is een voorbeeld van ons typische methodologie-overzicht:
Deze online peiling van SurveyMonkey werd uitgevoerd op 5 en 6 januari 2017 onder een nationale steekproef van 1725 volwassen van 18 jaar en ouder. Respondenten voor deze enquête werden geselecteerd uit een kleine 3 miljoen mensen die elke dag enquêtes invullen op het SurveyMonkey-platform. Data voor deze week zijn gewogen voor leeftijd, ras, geslacht, opleiding en geografische locatie met gebruik van de American Community Survey van het Amerikaanse Census Bureau om de demografische samenstelling van de VS weer te geven. De gemodelleerde foutschatting voor deze enquête is plus of min 3,5 procentpunten. De volledige resultaten vindt u hier.
Hier heeft de gemodelleerde foutschatting van plus of min 3,5 procentpunten dezelfde interpretatie als in het bovenstaande voorbeeld van de foutmarge. In elke blogpost of rapport vermelden we altijd de datums waarop de enquête werd gehouden, het aantal respondenten, een korte omschrijving van onze weegmethodologie en de gemodelleerde foutschatting voor de enquête.
Belangrijk: omdat we een online-enquête organisatie zijn, gaan mensen er vaak vanuit dat onze onderzoeksenquêtes worden beheerd via een select panel. Dit is niet juist. SurveyMonkey heeft weliswaar een panel van respondenten dat beschikbaar kan worden gesteld aan klanten, maar we gebruiken dit panel zelden voor het werven van respondenten. Onze methodologieverklaring geeft altijd aan hoe we onze steekproef van respondenten hebben verkregen en hoe we onze resultaten hebben gewogen.
Meer weten over data?
Bij SurveyMonkey werken we dagelijks met data op allerlei gebieden en over allerlei onderwerpen. Hieronder volgen een aantal recente voorbeelden van de inzichten die we hebben verzameld op basis van betrouwbare gegevens:
Waardering voor Trump: Zie hoe we over een langere periode wekelijkse gegevens hebben verzameld over het waarderingscijfer van President Trump. Bekijk hier het archief.
Consumentvertrouwen: In 2018 en 2010 publiceerden we een index van consumentvertrouwen op basis van de huidige financiële gezondheid van individuen en wat hun verwachtingen zijn voor de toekomst. Bekijk hier het archief.
Vertrouwen van kleine bedrijven: Elk kwartaal vragen we, in samenwerking met het Amerikaanse nieuwsnetwerk CNBC, aan kleine ondernemers naar het huidige klimaat voor kleinbedrijven en wat hun verwachtingen zijn voor de toekomst. Bekijk hier het archief.
Partners: We hebben nu meer partnerschappen dan ooit tevoren. Bekijk onze recente resultaten gepubliceerd door NBC News, Axios, FiveThirtyEight, The New York Times, ESPN, Vanity Fair’s Hive & theSkimm, OZY en CNBC.
Wilt u met mensen praten over de zaken die belangrijk zijn voor u?
SurveyMonkey Audience is een afzonderlijk hulpmiddel met een andere methode voor het werven van respondenten. In Audience doen respondenten enquêtes in ruil voor donaties aan het goede doel en klanten kunnen betalen voor meningen. De peilingsmethode die wordt omschreven op deze pagina is niet te koop. Het is het perfecte hulpmiddel om te gebruiken voor onderzoek naar concept testen, contentmarketing en meer.
Wie zit er achter het onderzoek?
SurveyMonkey werkt met een team van enquêtemethodologen: wetenschappers die onderzoek doen naar enquêtes, peilingen, publieke opinie en dataverzameling. Deze experts op het gebied van de methodologie voor enquêtes weten precies hoe u enquêtes moet structureren, vragen moet stellen en data moet analyseren om nauwkeurige resultaten te krijgen.
Meer hulpbronnen bekijken

Lijst met toolkits
Ontdek onze toolkits, waarmee u optimaal profiteert van feedback voor uw functie of sector.

Enquêtesjablonen
Bekijk meer dan 400 door experts geschreven, aanpasbare enquêtesjablonen. Maak en verzend snel interessante enquêtes met SurveyMonkey.

Calculator voor de p-waarde: de p-waarde berekenen
Gebruik onze calculator om de p-waarde te berekenen. En leer hoe u de p-waarde berekent en interpreteert in onze stapsgewijze handleiding.

U vraagt, wij bouwen: onze nieuwe functie voor meervoudige enquête-analyse is klaar voor gebruik
Met de nieuwe meervoudige enquête-analyse van SurveyMonkey kunnen gebruikers resultaten op één scherm combineren en analyseren.